
Data in UTF form can be confusing, and adding endianness can be overwhelming. I have great news, as the Byte Order Marker can help remove this confusion when opening a file or receiving a file.
A byte order mark (BOM) are the hexadecimal numbers FE FF which are placed at the beginning of a file, or data stream, which are used to automatically determine the type of encoding of the data. It is common to write programs in many languages, and the way that non-english ASCII characters are shown is by using different encodings. Byte Order Mark should be invisible to the user, and the programs should automatically read this data and decode the text appropriately.
There is an issue with just writing the text UTF16LE, which means Unicode Transformation Format in 16-bit blocks in Little Endian format. UTF is the way that characters are converted to numbers and back to characters again by the computer.
In the early days of computers, most of the text was written in English, which required about 128 characters to include capitals, small letters, and most accent characters. When other languages were starting to be on the internet, there quickly needed to be more characters than just those for English. The characters were expanded to UTF-16, and when more unique characters were needed, and an example is with the many characters in the Mandarin (Chinese) language, then UTF-32 was needed.
Another issue was that not all computers stored information the same, and Intel processors wrote data in Little Endian (LE) format, while old Mac computers wrote data in Big Endian (BE) format, and these formats were also added onto the end of the UTF type.
With all of these different format types, then there needed to be a way to detect the format of a text document or html that was sent over the internet. This was when the Byte Order Mark (BOM) was created. When the hexadecimal value &hFEFF is added with encoding, then the value would change depending on the UTF and Endian type. Below are the values of &hFEFF when the first 32 bits are read by the computer.
Table 1. Byte Order Mark Values for UTF and Endian Type
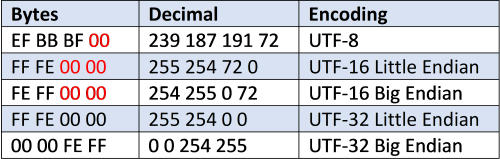
It is quite common for text programs to have the &HFEFF values placed at the beginning of the file before the first letter of text, so that the computer knows how to decode the UTF and Endian type and have the remaining characters viewed properly by the user. Make sure to ignore the red byte values, as these values will change based on the first letter that is typed in the text document and is not related to UTF type.
There is ambiguity between UTF-16LE and UTF-32LE, as they have the same byte order marker data. Although it is possible that the firstletters of a document in a UTF-16 LE document are nil characters, it is extremely rare! If nill characters are a possibility for your document, then rely on a different form, such as UTF-16 BE or UTF-32 BE.
An example was created to show how the data is added to a file that is saved and read on the desktop screen of the computer, and has the filename SampleBOM.txt. Below is a screen grab of the running program.
Figure 1. Byte Order Marker Program Screen Grab
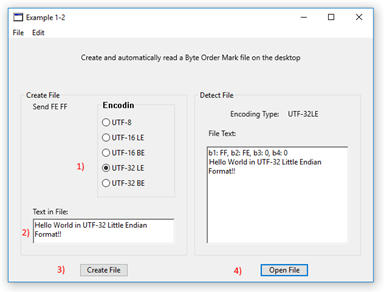
To use this program, first select the encoding type of the file that you wish to create. Next, type text that will appear in the body of the text document, then press the Create File pushbutton and a text file with the name SampleBOM will appear on the desktop. To open the file and detect the encoding type, press the Open File pushbutton and the encoding type will be displayed in a label, and the prefix values for bytes 1 through 4 are shown before the text in the textarea control. In this example the UTF-32 LE (32-bit Little Endian) format is created and when the &hFEFF byte order mark is read in UTF-32 LE format, then the byte values are FF FE 0 0 which matches the values in the above table.
Figure 2. Hex Editor File Data
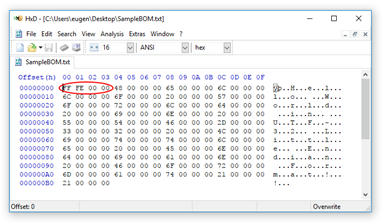
When the file is opened in a hex editor, the first four bytes of data are properly created for a UTF-32 Little Endian format with FF FE 00 00 numbers before the text.
To create this example, groupboxes and textarea controls were added with code in the Create File and Open File pushbutton action events.
Code 1. Create BOM File
|
Sub Action() Handles Action //Create new text data document Dim doc as FolderItem = SpecialFolder.Desktop If doc <> Nil Then Dim f as FolderItem = doc.Child("SampleBOM.txt") If f <> Nil then Dim t as TextOutputStream = TextOutputStream.Create(f) //Create a string with the correct encoding Dim s as String If RBUTF8.Value = True then s = ConvertEncoding(Chr(&hFEFF) + TACreateText.Text, Encodings.UTF8) ElseIf RBUTF16LE.Value = True Then s = ConvertEncoding(Chr(&hFEFF) + TACreateText.Text, Encodings.UTF16LE) ElseIf RBUTF16BE.Value = True Then s = ConvertEncoding(Chr(&hFEFF) + TACreateText.Text, Encodings.UTF16BE) ElseIf RBUTF32LE.Value = True Then s = ConvertEncoding(Chr(&hFEFF) + TACreateText.Text, Encodings.UTF32LE) ElseIf RBUTF32BE.Value = True Then s = ConvertEncoding(Chr(&hFEFF) + TACreateText.Text, Encodings.UTF32BE) End If //Write the string to the file t.Write(s) t.Flush t = Nil End If End If End Sub |
The first parts of this code have the folder located on the desktop and has the filename SampleBOM.txt. A file with this name is then created and the format encoding type is created that is based on the Radio Button (example RBUTF16BE) that has been selected. The string that is encoded is converted to the correct type with the ConvertEncoding method in the If-Else command. Data is written to the file and then the file has the &hFEFF prefix with text from the text area added to the file.
Reading a BOM file requires the first four bytes of data to be read and then the pattern is checked for the type of UTF and endianness. Below is the code for our example.
Code 2. Reading a BOM File
|
Sub Action() Handles Action //Open UTF data document Dim doc as FolderItem = SpecialFolder.Desktop.Child("SampleBOM.txt") If doc <> Nil Then Dim f as New Xojo.IO.FolderItem(doc.NativePath.ToText) //Make sure the file exists If f <> Nil then Dim b as Xojo.IO.BinaryStream b = Xojo.IO.BinaryStream.Open(f, Xojo.IO.BinaryStream.LockModes.Read)
Dim b1 as UInt8 = b.ReadUInt8 Dim b2 as UInt8 = b.ReadUInt8 Dim b3 as UInt8 = b.ReadUInt8 Dim b4 as UInt8 = b.ReadUInt8 Dim Encdng as Xojo.Core.TextEncoding
If (b1=&hEF) And (b2=&hBB) and (b3=&hBF) Then Encdng = Xojo.Core.TextEncoding.UTF8 LblEncoding.Text = "UTF-8" //Help remove UTF-16LE ambiguity ElseIf (b1=&hFF) And (b2=&hFE) and ((b3<>&h00) or (b4<>&h00)) Then Encdng = Xojo.Core.TextEncoding.UTF16LittleEndian LblEncoding.Text = "UTF-16LE" ElseIf (b1=&hFE) And (b2=&hFF) Then Encdng = Xojo.Core.TextEncoding.UTF16BigEndian LblEncoding.Text = "UTF-16BE" ElseIf (b1=&hFF) And (b2=&hFE) and (b3=&h00) and (b4=&h00) Then Encdng = Xojo.Core.TextEncoding.UTF32LittleEndian LblEncoding.Text = "UTF-32LE" ElseIf (b1=&h00) And (b2=&h00) and (b3=&hFE) and (b4=&hFF) Then Encdng = Xojo.Core.TextEncoding.UTF32BigEndian LblEncoding.Text = "UTF-32BE" Else //default to UTF-8 LblEncoding.Text = "UTF-8" Encdng = Xojo.Core.TextEncoding.UTF8 End If b.Close
//Open the file Dim TxtFile as Xojo.IO.TextInputStream TxtFile = Xojo.IO.TextInputStream.Open(f, Encdng) Dim s as String s = TxtFile.ReadAll TextArea1.Text = "b1: " + Hex(b1) + ", b2: " + Hex(b2) + ", b3: " + Hex(b3) + ", b4: " + Hex(b4) +_ EndOfLine + s TxtFile.Close End If End If End Sub |
A text file path which is located on the desktop with the name SampleBOM is created and then opened. The first four binary bytes are read from the file and are placed in the Uint8 variables. A variable to hold the encoding type has also been created. An If-Else comparison is created to determine which type of encoding from the first four bytes. The bytes follow the above chart and a small amount of code has been added to minimize the chance of confusing UTF16LE with UTF32LE. Byte 3 and 4 for UTF16LE are checked for having bytes other than 00, which means that there is a first letter in the text. An Else command is used to default the encoding to UTF8 if one has not been found. The binary stream is then closed and the four-byte values are shown and then the text in the file is displayed on a line below it.
This example shows how to use the Byte Order Mark to encode the data and automatically decode a text file by reading the Byte Order Marker.
Here is the program for this article: BOMExample.zip.
| This example was created on Windows 10 with Xojo on 5 Nov 2017 |